STM32+i.MX6ULL异构通信下对比轮询和零拷贝性能测试
1、CPU占用率对比测试
STM32端保持全速发送,对比驱动中使用CPU轮询加传统read()方式,以及驱动中使用DMA加零拷贝方式的CPU占用率
使用top查看CPU占用率前,需要让进程在后台运行,且不能把输出写到终端中
1 | ./enoseApp > /dev/null 2>&1 & |
查看进程的CPU占用率
1 | top -p $(pidof enoseApp) |
后台只有1个进程,用fg命令把它拉回前台,直接结束就可以了
使用CPU轮询加传统read()方式,CPU占用率高达98%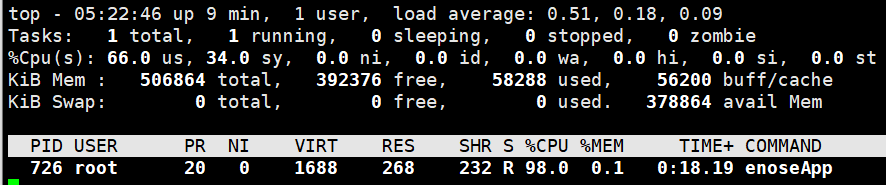
使用DMA加零拷贝方式,CPU占用率下降至1%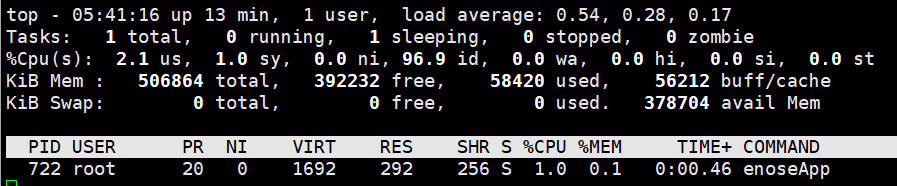
2、端到端延时测试
在10MHz的SPI传输速率下,测试从STM32准备好数据,拉高同步引脚,到应用程序在接收到数据后,将一个空闲引脚拉高之间的时间。
端到端延时1.3ms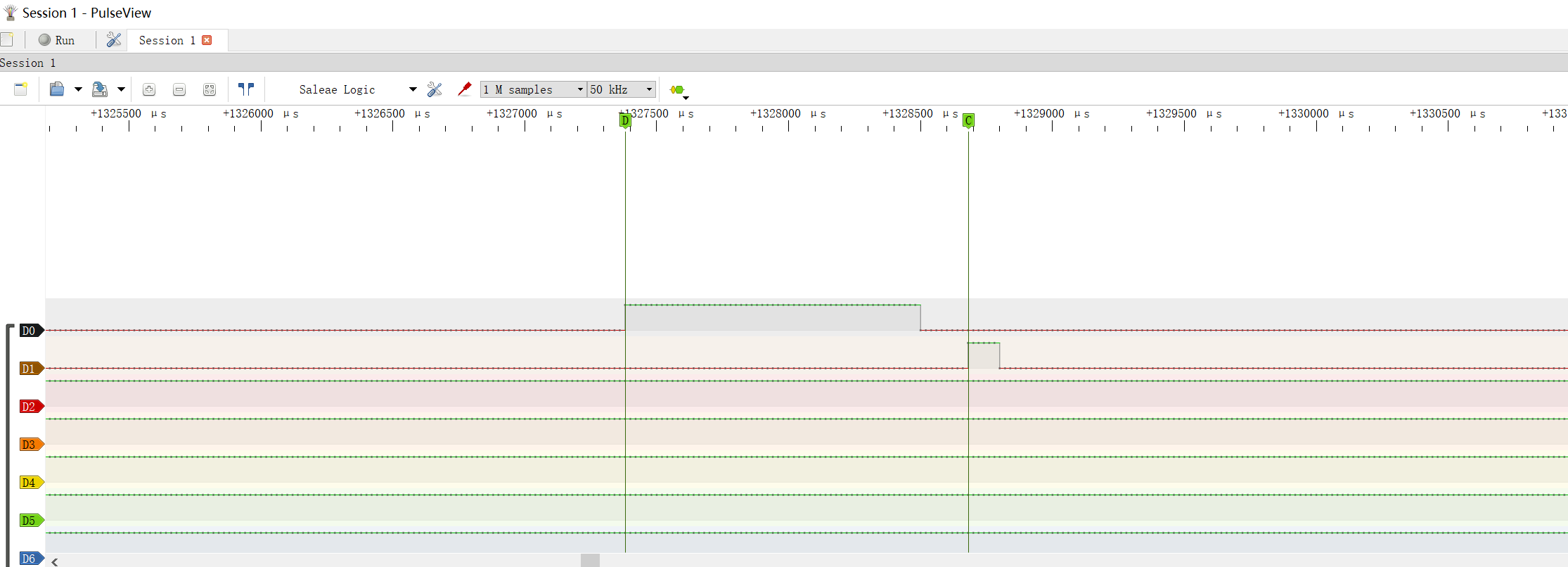
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 青右!